Numpy ve Pandas
Numpy

Numpy, genel olarak bilimsel hesaplamalar için kullanılan bir python paketidir. Çok boyutlu dizileri kolayca ve hızlıca kullanmamızı sağlar. Daha çok makine öğrenmesi, derin öğrenme ve görüntü işleme gibi işlemlerde çok sık kullanılır. C++ tabanlı bir kütüphane olduğu içinde hız konusunda başarılıdır. Numpy ile oluşturulan diziler başlangıçta oluşan sabit boyutlu dizilerdir. Eğer daha sonra bu diziye bir şey eklemek istediğinizde eski diziyi silip yeni bir dizi oluşturur.
Numpy’da çok boyutlu dizileri anlamak için aşağıdaki resime bakılabilir. Kendi logosundan da aynı sonucu çıkarabilirsiniz.
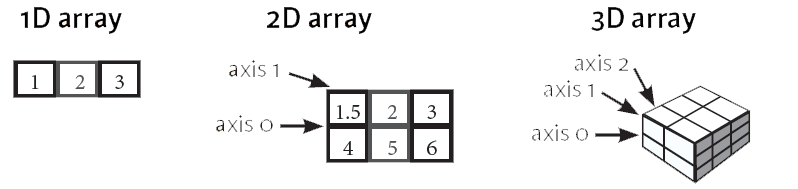
Bu dizi tiplerine örnekler verelim. Tek boyutlu dizi
[1,2,3,4,5]
2 boyut dizi
[ [1, 2, 3], [4, 5, 6] ]
3 boyutlu dizi
[
[ [1, 2, 3], [4, 5, 6] ],
[ [7, 8, 9], [1, 2, 3] ]
]
Bu dizi tiplerini herhangi bir programlama dilinde de yapabiliriz. Burada Numpy’ın özelliği, bu dizileri kolay ve hızlı şekilde kullanılabilmektir.
Örnek vermek gerekirse elimizde iki tane dizi olsun.
x = [1,2,3]
y = [4,5,6]
bunları toplamak istediğimizde
x = [1,2,3]
y = [4,5,6]
z = []
for i in range(len(x)):
z.append(x[i] + y[i])
print(z)
[5, 7, 9]
Ama bunu Numpy ile yapmak istediğimizde durum çok daha kolay.
x = np.array([1,2,3])
y = np.array([4,5,6])
z = x+y
print(z)
array([5, 7, 9])
Örnek dizinin son halinin toplamını almak istediğimizde;
print(z.sum())
21
Bu gibi bir çok fonksiyonel işlemi Numpy’da bulabilirsiniz. Ayrıntılı bakmak için kaynaklara göz atabilirsiniz.
Pandas
Pandas yüksek performanslı, kullanımı kolay veri yapılandırma ve veri analizi yapabileceğimiz bir kütüphanedir. Pandas ile excel, csv, json vs. dosyaları okuyup, yazabilirsiniz.
Örnek bir csv dosyasını okumak istersek;
df = pd.read_csv("/tmp/test.csv")
İstersek dosyanın içinde sadece seçtiğimiz sütunlarıda alabiliriz.
Pandas’daki dataframe ve seriler en önemli veri yapılarıdır. Dataframe nesnesi 2 boyutlu bir nesnedir. Index ve column olarak oluşur. Bunu aslında bir excel dosyası gibi düşünebilirsiniz. Index karşılığı satırlar, Column karşılığı ise sütunlardır.
Örnek bir dataframe aşağıdaki gibi olabilir.
| yas | boy | kilo | cinsiyet | |
|---|---|---|---|---|
| 0 | 20 | 185 | 85 | erkek |
| 1 | 30 | 164 | 55 | kadın |
| 2 | 40 | 170 | 80 | erkek |
| 3 | 25 | 170 | 57 | kadın |
| 4 | 23 | 175 | 73 | erkek |
| 5 | 60 | 160 | 60 | erkek |
| 6 | 17 | 170 | 80 | erkek |
| 7 | 28 | 172 | 62 | kadın |
| 8 | 44 | 166 | 58 | kadın |
Buradaki index bölümünü seriler olarak oluşturup istediğimiz gibi filtreleyebiliriz. Örneğin index bölümünü timeseries olarak oluşturabiliriz veya index sütunun diğer sütunlarla değiştirebiliriz. Tarihsel olarak filtreleme yapabiliriz. Bahsettiğim gibi excel gibi düşünebilirsiniz. Excel’de nasıl filtreler kullanılıyorsa dataframelerde de kullanabiliriz.
Örnek bir dataframe oluşturmak istediğimizde;
>>> df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
>>> df
a b
0 1 2
1 3 4
yapmamız yeterli olacaktır. Filtrelemekten bahsetmiştik. Yukarıdaki yaş, boy tablosundaki yaşı 20 üstü olanları almak istediğimizde;
df.loc[df["yas"] > "20"]
veya dataframe hakkında bilgi almak istediğimizde şu satırları kullanabiliriz.
df.info()
df.shape
df.describe()
Ayrıntılı bilgiler için Pandas websitesi.
kaynaklar
- Python Numpy Array Tutorial (article) - DataCamp
- NumPy’a Hızlı Başlangıç – Veri Bilimcisi
- Python Pandas DataFrame
- Python Pandas ile Temel İşlemler-1 (Dosya okuma, Sütun İsimlendirme) – datascience.istanbul
- Pandas Cheat Sheet