LLM Dünyasına Giriş: Transformer Mimarisi

Giriş
Transformer mimarisi, 2017 yılında Ashish Vaswani ve ekibinin “Attention is All You Need” makalesiyle tanıtıldı. Bu yapı, RNN ve LSTM gibi sıralı modellerin yavaşlığını ve uzun bağımlılıkları öğrenmedeki zorluklarını ortadan kaldırarak doğal dil işleme (NLP) alanında devrim yarattı. Günümüzde GPT, BERT, T5 ve benzeri tüm büyük dil modelleri bu mimariyi temel alır.

Transformer’ın Temel Mantığı
Transformer mimarisi 2017’de “Attention is All You Need” makalesiyle tanıtıldı. Bu yapı, RNN ve LSTM gibi sıralı modellerin dezavantajlarını ortadan kaldırdı ve NLP’de devrim yarattı. Günümüzde GPT, BERT, T5 gibi büyük dil modelleri de temelde Transformer üzerine kurulu.
Transformer, dizilerdeki öğeleri eşzamanlı işler. Bu, onu RNN’lerden çok daha hızlı yapar. Ana yenilik attention (dikkat) mekanizmasıdır: Her kelime, diğer tüm kelimelere bakarak “hangi kelimelere daha çok dikkat etmeliyim?” sorusuna cevap verir. Böylece bağlam, özne, nesne, zaman, duygu gibi ilişkiler öğrenilir.
Mimari Yapı
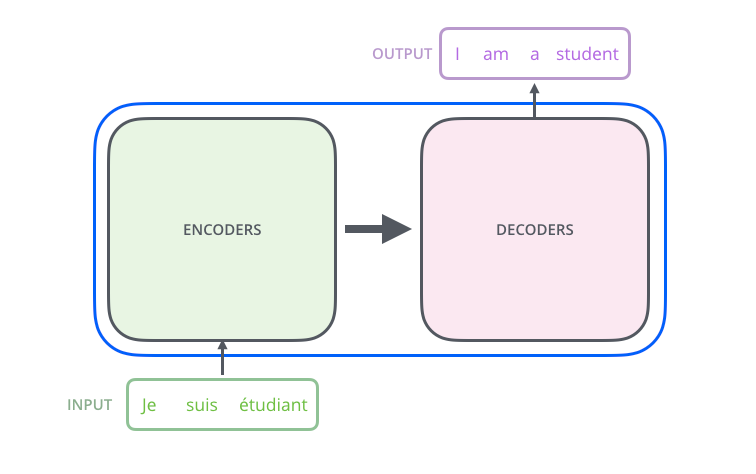
Transformer iki ana bileşenden oluşur:
🧩 Encoder
- Girdi dizisini işler.
- Her kelimeye embedding uygulanır.
- Ardından positional encoding eklenir (kelimenin cümledeki konum bilgisini taşır).
- Self-Attention katmanları ile her kelimenin diğerleriyle ilişkisi hesaplanır.
- Sonuçlar Feed Forward Network (FFN) katmanına aktarılır.
🧠 Decoder
- Encoder çıktısını alır.
- Kendi önceki çıktılarıyla masked self-attention uygular (geleceği görmez).
- Encoder’dan gelen bilgiyle encoder-decoder attention kurar.
- Son katmanda olasılıksal çıktı üretir (ör: bir sonraki kelime).
Embedding Katmanı
- Kelime veya token’ları sayılara çevirir.
- Her kelime anlamını taşıyan bir vektör haline gelir.
“Merhaba” → [0.25, 0.71, -0.33, ...] “Dünya” → [0.30, 0.65, -0.40, ...] - Model bu vektörleri eğitim sırasında öğrenir.
- Ardından positional encoding ile konum bilgisi eklenir.
Positional Encoding
- Modelin sıralama bilgisini alması gerekir.
- Her kelimeye pozisyonu belirten bir vektör eklenir.
- Bu bilgi sinüs ve kosinüs fonksiyonlarıyla üretilir.
- Böylece model kelime sırasi ve anlamını doğru şekilde işler.
Self-Attention Katmanı
- Transformer’ın en kritik kısmı.
- Her kelimenin cümledeki diğer kelimelerle olan ilişkisini bulmaya çalışır.
- Hem encoder’da hem decoder’da bulunur.
- Birden fazla self-attention işlemi bir araya gelince Multi-Head Attention oluşur.
- Model anlam, zaman, bağlam gibi birçok ilişkiyi aynı anda öğrenir.
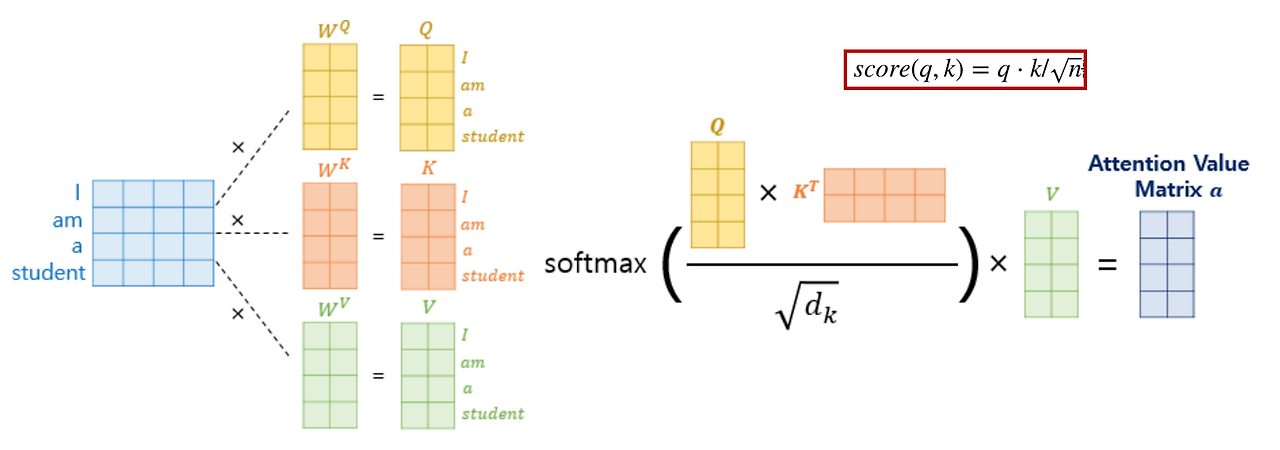
Self-Attention’da embedding’den gelen veri üzerinde üç ana vektör hesaplanır:
- Q (Query): Hangi kelimelere dikkat etmeliyim?
- K (Key): Diğer kelimeler için ne kadar önemliyim?
- V (Value): Benim anlamım nedir?
👉 Q soruyu sorar
👉 K cevabı belirler
👉 V bilgiyi taşır
Bu üçü birlikte çalışarak modelin kelimeler arasındaki ilişkileri anlamasını sağlar. Tüm bu işlemler — Q, K, V oluşturma → skor hesaplama → softmax → ağırlıklı ortalama — Self-Attention katmanının içinde gerçekleşir.
Bağlamsal İlişki Örneği
Örneğin “kedi” ve “balık” kelimeleri embedding ile vektörlere dönüştürülür. Self-Attention bunlar arasındaki ilişkiyi inceler. “Kedi balıkla ilişkili mi?” sorusunu Q ve K çarpımıyla bulur. Eğer ilişki yüksekse, model “kedi”nin anlamını “balık”tan gelen bilgiyle günceller. Model kelimeler arasındaki bağlamsal ilişkileri böylece öğrenir.
✅ Kısa Özet
- Embedding: Kelimeleri sayılara çevirir.
- Positional Encoding: Sıra bilgisini ekler.
- Self-Attention: Kelimeler arasındaki ilişkileri bulur.
- Decoder: Öğrenilen bilgilere göre yanıt üretir.
🍏 Sonuç
Transformer mimarisi, derin öğrenme tarihinde bir dönüm noktası olmuştur. RNN ve LSTM modellerinin sıralı yapısına göre çok daha hızlı ve verimli çalışarak dilin bağlamsal yapısını çözmeyi başarmıştır.
Self-Attention mekanizması sayesinde model, cümledeki her kelimenin diğerleriyle olan ilişkisini anlayabilir. Bu sayede metinleri, anlamı kaybetmeden paralel biçimde işler.
Günümüzde GPT, BERT, T5 gibi dev modellerin başarısının temelinde Transformer yapısı vardır. Kısacası Transformer, sadece bir mimari değil, modern yapay zekânın dil anlama yeteneğinin çekirdeğidir.
Kaynaklar
- The Illustrated Transformer
- Transformer Mimarisi Türkçe Anlatım Part 1: Embeddings
- Transformer Mimarisi Türkçe Anlatım Part 2: Self-Attention
- Transformer Mimarisi Türkçe Anlatım Part 3: Transformer’a Adım Adım